El avance vertiginoso de la tecnología ha causado que muchas empresas se vean atrapadas en un dilema entre la necesidad de datos rápidos y la validez científica de sus investigaciones. En este contexto, la investigación sintética impulsada por inteligencia artificial se presenta como una solución atractiva, pero también trae consigo un serie de riesgos significativos. La falta de gobernanza y validación en estos procesos puede llevar a que los resultados sean engañosos y, en última instancia, se traduzcan en malas decisiones empresariales. Mientras que el ahorrarse tiempo y dinero es un atractivo sin duda importante, las organizaciones más competidoras son las que comprenden las limitaciones de las herramientas sintéticas, combinándolas adecuadamente con métodos más tradicionales para asegurar resultados precisos y confiables.
Uno de los principales desafíos que enfrenta la investigación sintética es la dependencia en modelos de lenguaje grandes (LLMs), que no siempre cumplen con las expectativas de resultados representativos. Estos sistemas, al ser alimentados con información, pueden caer fácilmente en sesgos que distorsionan la realidad asociada a sus respuestas. En muchos casos, los encuestados sintéticos parecen ajustarse a lo que creen que se esperaría de ellos, lo que puede resultar en la validación de conceptos mediocres. Este fenómeno, conocido como el principio de Pollyanna, intensifica la necesidad de mejorar la calidad de los datos y la precisión en la toma de decisiones a partir de resultados sintéticos, pues estas herramientas no son infalibles.
Para obtener resultados efectivos de la investigación sintética, el proceso de ajuste fino resulta crucial. Esto implica nutrir a los LLMs con datos específicos de la compañía, lo que permite que los modelos generen respuestas más precisas y contextualizadas. Un estudio reciente demostró que la sobreestimación de la disposición a pagar en un caso concreto fue corregida significativamente al incorporar datos de encuestas ya existentes. Este enfoque no solo mejora la fiabilidad de los datos sintéticos, sino que también proporciona una ventaja competitiva al utilizar información alineada a situaciones del evento real, transformando así la investigación en una herramienta más potente y decisiva.
La metodología conocida como entrenar-sintético, probar-real (TSTR) representa un avance prometedor. Este método permite que se entrenen modelos con datos sintéticos y luego se validen con muestras reales para verificar su capacidad de predicción. Este enfoque no solo ahorra tiempo y costos para las empresas que buscan insights valiosos, sino que también contribuye a construir la confianza necesaria en su validez. Al adoptar medidas como estas, las organizaciones pueden avanzar en el ámbito de la investigación sintética, maximizando su valor al tiempo que minimizan riesgos relacionados con el uso erróneo de la inteligencia artificial.
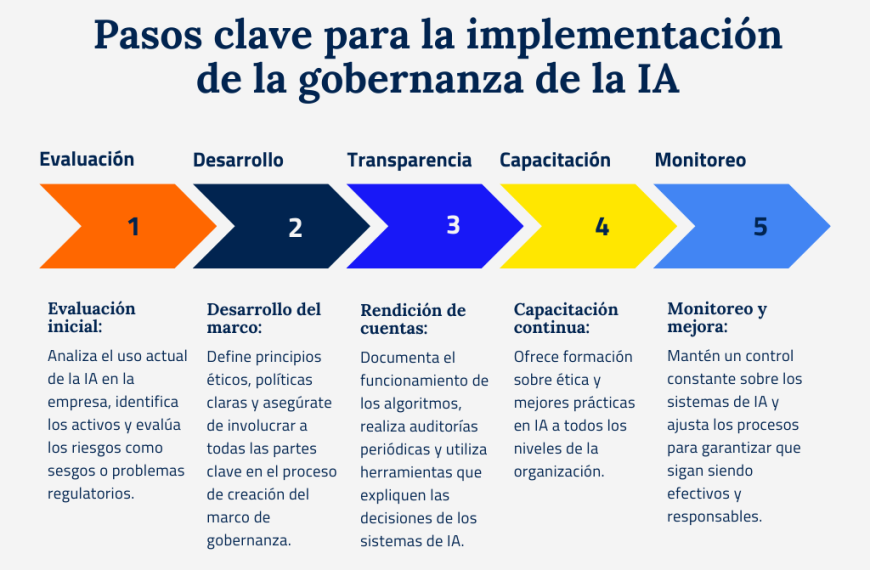
Finalmente, es fundamental establecer gobernanza y transparencia en el uso de la investigación sintética. A medida que el poder de estas herramientas aumenta, se vuelve crucial que los investigadores y lectores comprendan las limitaciones y metodologías detrás de los resultados. Esta transparencia no solo aborda preocupaciones éticas, sino que también permite fomentar la confianza en los procesos llevados a cabo. Con un enfoque equilibrado entre la confianza en la tecnología y la verificación empírica, las organizaciones pueden afrontar los desafíos del marketing actual, asegurando que su visibilidad no solo se mantenga, sino que se recupere y se fortalezca frente a una competencia creciente.